抢占式实例的自动监控与恢复
文章目录
info
文章内所有功能 redc 已支持
抢占式实例的自动监控与恢复
这个问题的背景
搞红队基础设施的都知道,云上资源开销是个绕不过去的问题。一个代理池场景随随便便就是好几台 ECS,按量计费一天下来费用不低。后来我们在 RedC 里把阿里云和 AWS 的代理场景全部切到了抢占式实例(Spot Instance),成本直接砍掉 60%~90%,效果立竿见影。
但抢占式实例有个众所周知的问题:它随时可能被云厂商回收。
实际遇到
有一天,我开了个阿里云的代理池场景,几十台抢占式 ECS,跑着跑着其中部分被回收了。直到发现代理可用率掉了一半才上控制台看——原来是被释放了。
这就引出了两个很现实的问题:
- 怎么知道实例被回收了? 云厂商的中断通知机制各不相同,有的要接 API,有的要轮询元数据服务,而且只能在实例内部获取。对于一个管理多个场景、跨多个云厂商的工具来说,逐一对接太碎片化了。
- 知道了之后怎么办? 手动上去重新开?那还不如用按量的。能不能自动把被回收的实例补回来?
思路:不依赖云厂商通知,从外部探测
一开始想的是去对接各个云厂商的中断通知 API,但想了想放弃了。原因:
- 阿里云的抢占式实例中断事件可以通过 CloudMonitor 事件订阅拿到,但需要额外配置事件规则、回调地址
- AWS 可以用 EventBridge 监听 Spot 中断警告,也挺麻烦
- 腾讯云、火山引擎各有各的接口
这些方案对一个本地运行的 GUI 工具来说,太重了。
换个角度想——抢占式实例被回收之后,最直观的表现是什么?就是机器没了,连不上了。
所以最终选了一个最简单粗暴的方案:定期 TCP 探测 SSH 端口。每隔一段时间,对所有运行中的 Spot 场景的公网 IP 做一次 22 端口探测。连不上,就说明实例大概率已经被回收了。
这个方案的好处是:
- 不依赖任何云厂商的特定 API
- 不需要在实例内部装 agent
- 对 RedC 已有的场景管理结构完全兼容
坏处也有——不够实时,探测间隔决定了你最晚多久能发现。不过对我们的场景来说,3 分钟的延迟完全可以接受。
具体怎么做的
整体架构
监控模块作为一个后台常驻 goroutine 运行,启动后按固定间隔执行扫描。流程大概是这样:
|
|
怎么判断一个场景是 Spot 实例
不是所有场景都用了抢占式实例,所以第一步是识别。做法很简单——扫描场景目录下的 .tf 文件,看有没有这几个关键字:
|
|
阿里云的 Spot 实例在 Terraform 里长这样:
|
|
AWS 的则是:
|
|
通过静态文本匹配就能判断,不需要调用云 API。
SSH 探测的细节
探测逻辑做了一些容错处理:
|
|
一次连不上不算数,连续 3 次都连不上才判定为回收。每次超时 10 秒,重试间隔 15 秒。这样单个 IP 的判定周期大约是 1 分钟,能有效过滤掉网络抖动导致的误报。
另外一个细节是 alerted 机制——已经报过警的 IP 不会重复报。用 caseID:ip 作为 key 记录,避免每一轮扫描都重复告警同一个已挂的实例。
自动恢复
检测到实例被回收后,如果用户开启了自动恢复选项,会触发 Terraform 的 plan + apply 操作。Terraform 的声明式特性在这里很好用——你声明了要 2 台实例,现在只剩 1 台,apply 一下自然会把缺的那台补回来。
但这里踩了一个坑。
RedC 里,场景启动后状态是 running,而 TfApply() 方法内部有一个状态检查:如果当前状态已经是 running,会直接拒绝执行并返回错误”场景正在运行中”。这个检查本来是防止用户误操作的,但在自动恢复场景下就有点碍事。
解法是绕过上层封装,直接调用底层的 TfPlan() 和 TfApply() 函数:
|
|
恢复成功后,还要做一件事:清除该场景的告警记录(ResetAlert)。因为恢复后实例的 IP 会变,旧 IP 的告警记录已经没意义了,而新 IP 需要能被正常监控。
实现效果如下
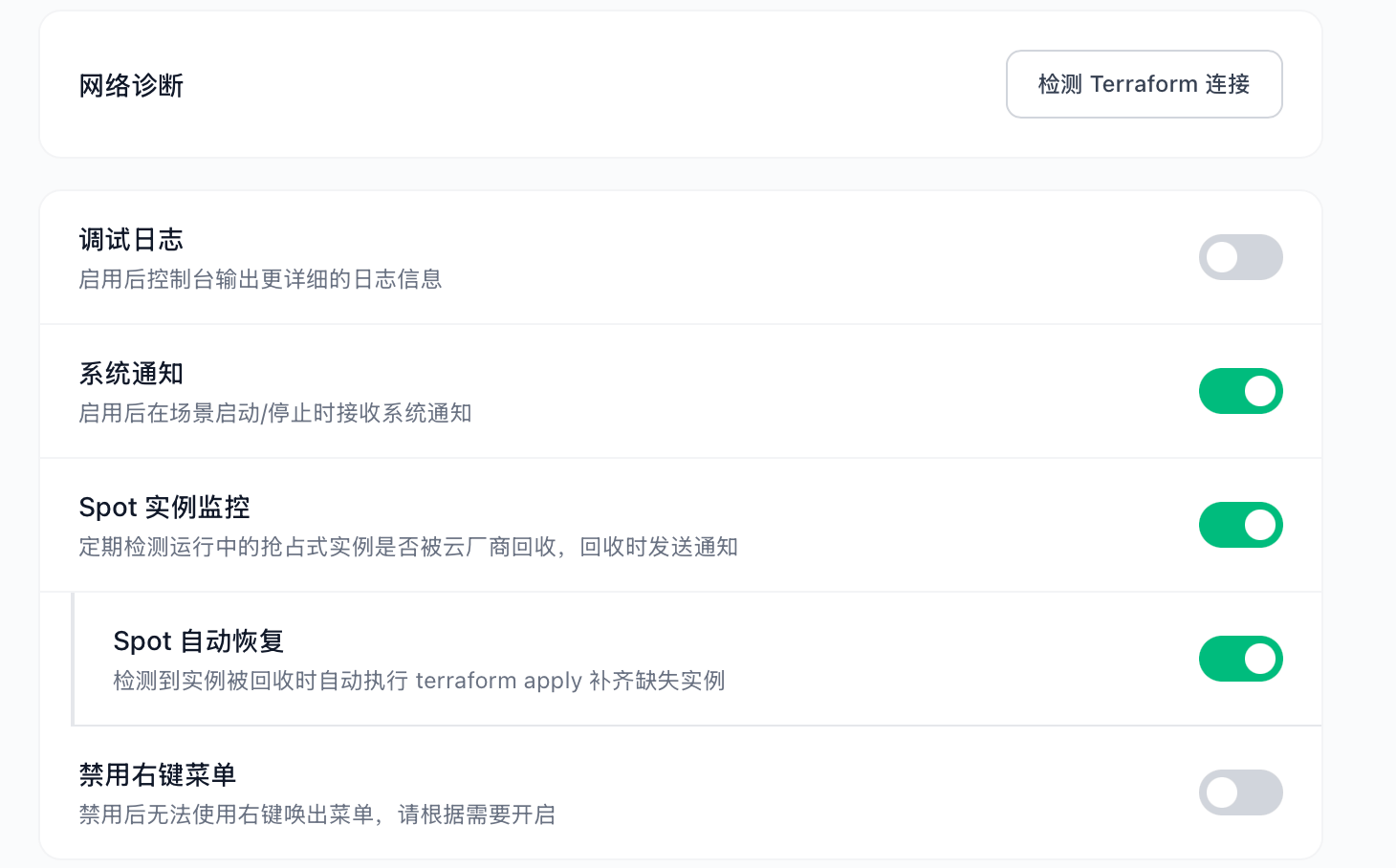
开启 spot 实例监控
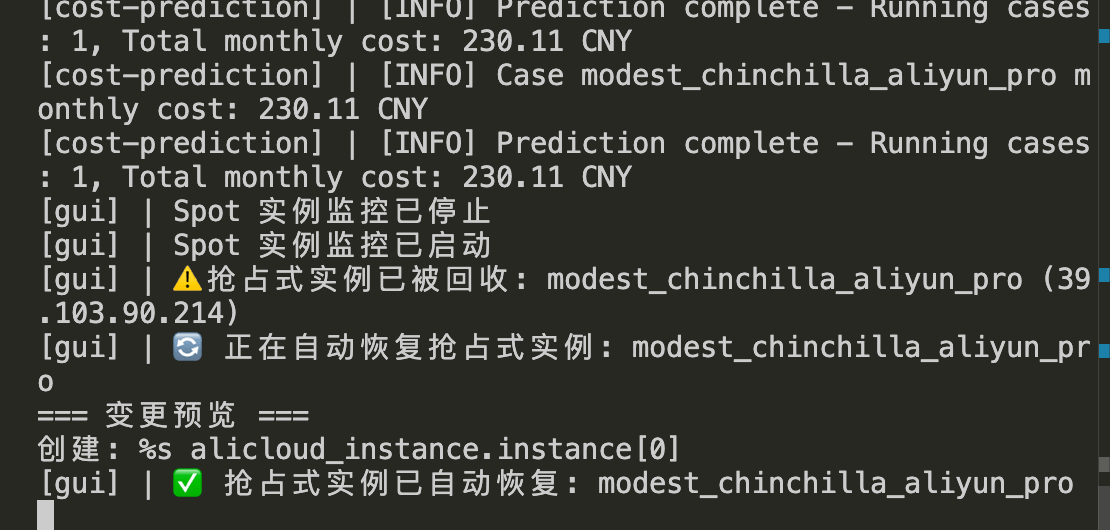
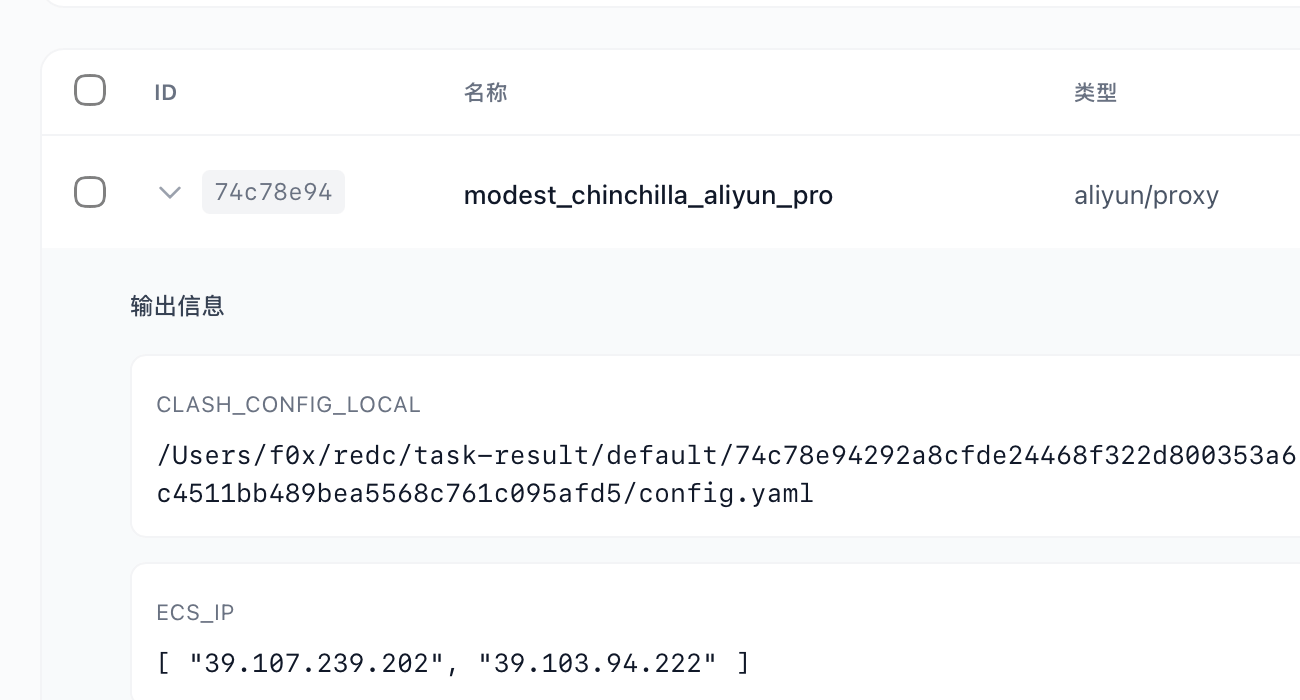
开个场景,验证一下,这里 一台 214,一台 222
手动把 214 释放掉
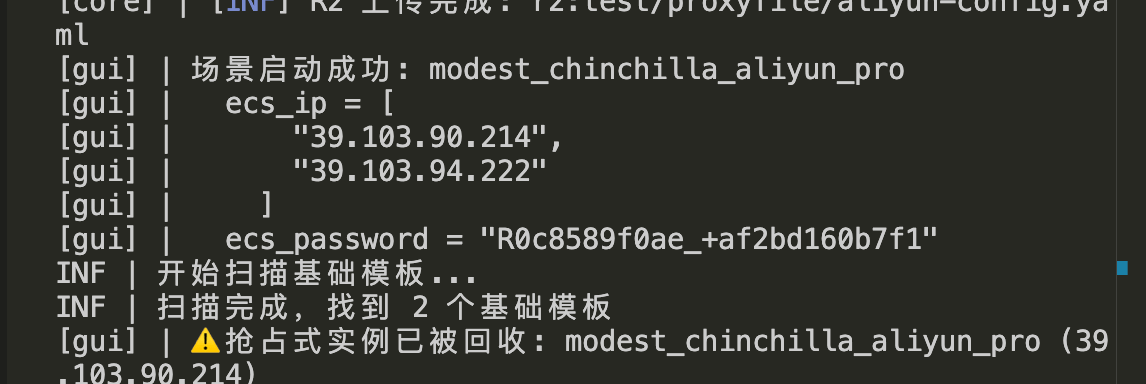
过一会,自动把 214 那台重新开启,222 未受到影响,场景恢复
通知集成
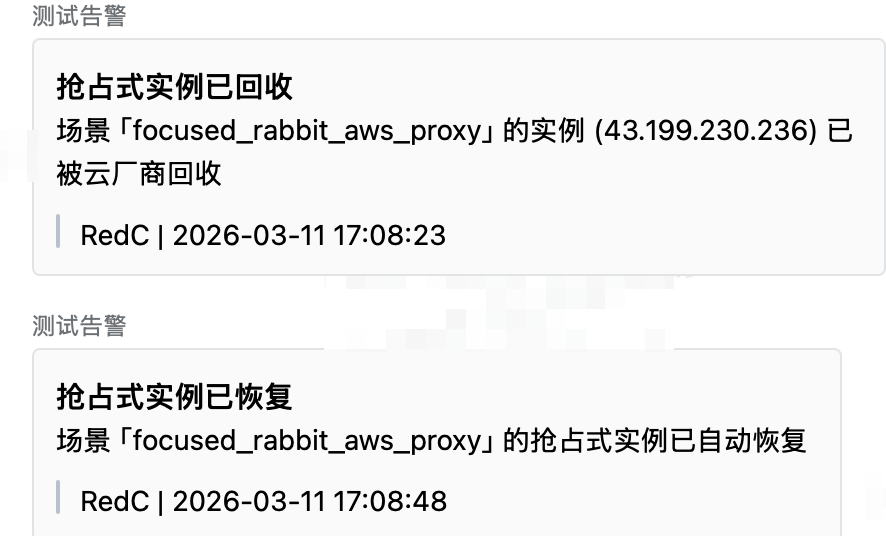
- 系统通知:macOS / Windows / Linux 原生桌面通知,适合人在电脑前的场景
- Webhook 推送:支持 Slack、钉钉、飞书、Discord、企业微信,适合团队协作或不在电脑前的场景
通知内容包括场景名、被回收的 IP、是否全部回收、自动恢复结果等。

做成可选项
因为 Spot 监控需要持续做 TCP 探测,对于不用抢占式实例的用户来说是没必要的开销。所以把它做成了设置页面里的一个开关,默认关闭,用的时候再打开。自动恢复也是单独的开关,可以只开监控不开恢复。
配置存在本地的 gui_settings.json 里,重启不丢失。
实际效果
目前这套方案,有几个实际的体验:
- 阿里云的抢占式 ECS 被回收后,大约 3 分钟内能检测到并触发恢复,新实例通常在 2 分钟内就起来了。整个中断窗口大约 5 分钟。
- AWS 的 Spot Instance 同理,探测 + 恢复的总时间差不多。
- 代理池场景里如果 2 台实例只回收了 1 台,Terraform apply 只会补那 1 台,不会影响另一台正在运行的实例,代理可用率不会归零。
对于红队基础设施的场景来说,这个恢复速度基本够用。
当然如果场景可用性要求特别高(比如不能断超过 1 分钟),那还是老老实用用按量实例把。
小结
- 不去对接各云厂商的中断通知,用 TCP 端口探测作为统一的健康检查手段
- 利用 Terraform 的声明式特性,apply 一下就能把被关闭的实例补回来
- 通知做多层覆盖,确保不会错过
文章作者 r0fus0d
上次更新 2026-03-12